Z pewnością nie chciałbyś, aby na twojej stronie były niedziałające linki lub prowadzące do strony, która nie istnieje. W przypadku małej strony można ręcznie sprawdzić, czy wszystkie linki działają, ale na większych stronach nie będzie to takie proste. Poza tym, jako programiści powinniśmy automatyzować powtarzalne czynności 🙂
Użyjemy bardzo fajnej biblioteki do sprawdzania popsutych linków, a jest to Broken Link Checker.
Ostatnio w pracy miałem okazję skorzystać z tej biblioteki. Zaimplementowałem sprawdzanie wszystkich linków w dokumentacji naszego produktu. Ostatecznie napisany skrypt jest bardzo prosty. Najpierw dokumentacja jest budowana, następnie uruchamiany jest http-server w folderze z bundlem aplikacji, i w końcu uruchamiane jest skanowanie linków na tej stronie.
Bibliotekę możemy używać na dwa sposoby: w wierszu poleceń oraz w kodzie poprzez API. Zaprezentuję obie opcje.
Instalacja: Musimy mieć zainstalowany NPM oraz Node w wersji wiekszej lub równej 14.
Użycie w wierszu poleceń
W celu użycia biblioteki w wierszu poleceń, zainstalujmy ją globalnie:
npm install broken-link-checker -g
Jeśli instalacja powiodła się, możemy sprawdzić dostępne argumenty:
blc --help
Typowe użycie w celu przeskanowania całej strony może wyglądać następująco:
# -r skanuje rekurencyjnie całą stronę, czyli również wszystkie podstrony
# -o zachowuje kolejność linków w jakiej pojawiają się na stronie
blc https://www.oskarkowalow.pl -ro
Powyższy skrypt uruchomi skanowanie strony internetowej. Tak wygląda fragment skanowania mojej strony:
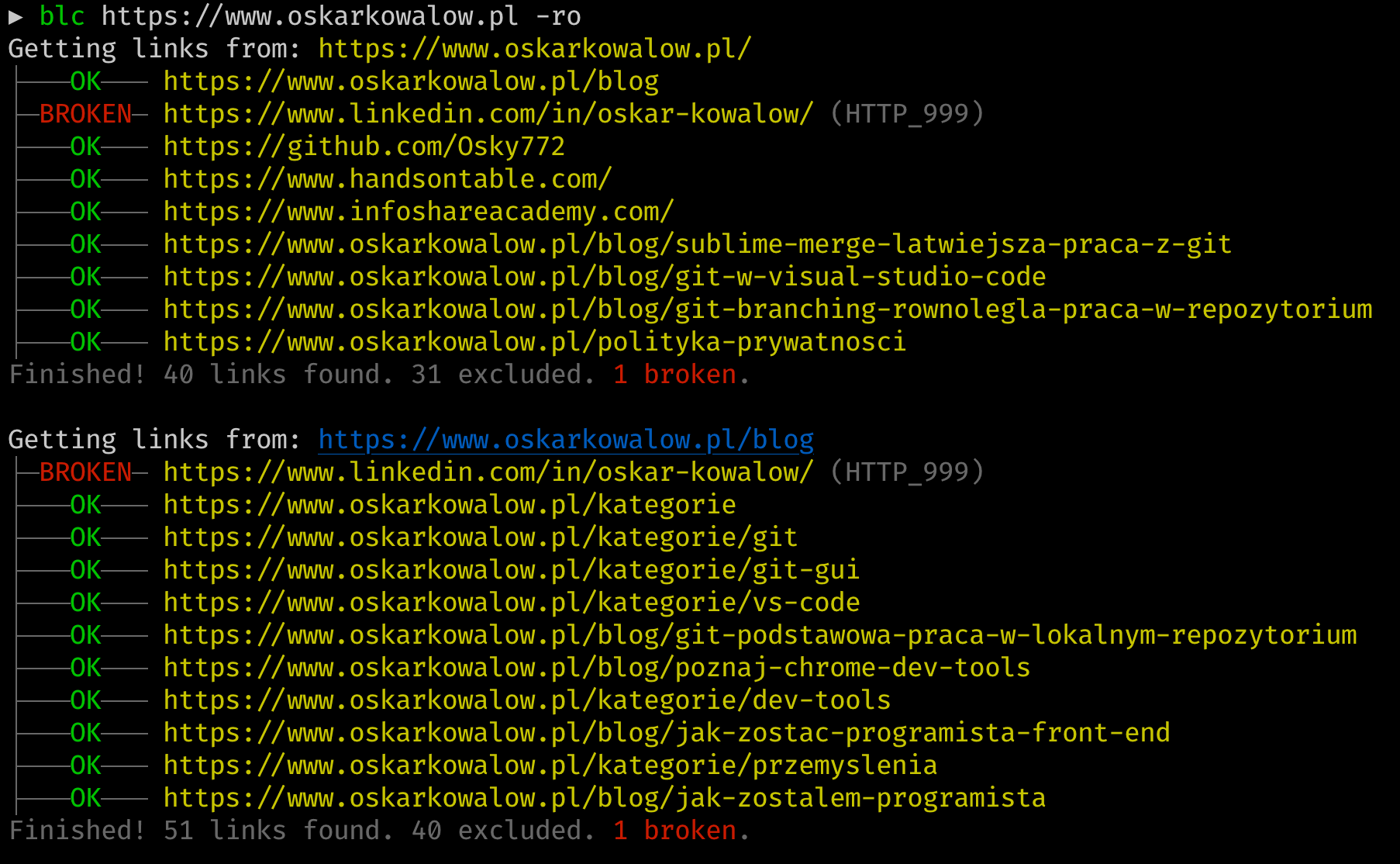
Wynik skanowania jest bardzo czytelny i wiadomo, które linki działają, a które nie. Widać jednak, że linki prowadzące do Linkedin wyrzucają błąd. To zachowanie jest nie do ominięcia i linki prowadzące do Linkedin zawsze będą zwracać ten błąd.
U mnie tak wygląda wynik zakończenia skanowania:
Finished! 682 links found. 578 excluded. 18 broken.
Elapsed time: 49 seconds
Moja strona jest jeszcze dość mała i skanowanie wszystkich podstron nie było zbyt czasochłonne.
Pomijanie linków
Możemy pomijać skanowanie wybranych linków, aby przyspieszyć skanowanie lub pozbyć się linków, które zawsze zwracają błąd:
--exclude-externallub-espowoduje pominięcie wszystkich linków do zewnętrznych serwisów,--exclude-internallub-ispowoduje pominięcie wszystkich wewnętrznych linków, a więc będzie sprawdzać tylko zewnętrzne linki,--excludepozwala na pomijanie różnych ścieżek i wybranych linków.
Tak może wyglądać pominięcie linków do Linkedin oraz podstrony “blog/kategorie”:
blc https://www.oskarkowalow.pl -ro \
--exclude linkedin \
--exclude /blog/kategorie
Skanowanie tylko jednej strony
Czasem skanowanie wszystkich podstron może być bardzo czasochłonne, szczególnie jeżeli mamy bardzo duży serwis do sprawdzenia. W takim wypadku wystarczy odjąć flagę -r:
blc https://www.oskarkowalow.pl -o
Użycie w kodzie
Biblioteka udostępnia API, dzięki czemu możemy użyć jej w kodzie. Przykładowo, możemy napisać skrypt w Node JS, który będzie sprawdzał wybrane linki na stronie zanim pójdzie ona na produkcję. Może to być kolejny krok w ramach testów w naszym Continues Integration.
Zainstalujemy bibliotekę lokalnie, wewnątrz naszego projektu:
# instalujemy jako dev dependencję, gdyż jest potrzebna tylko podczas developmentu
npm install --save-dev broken-link-checker
Stwórzmy nowy plik w którym umieścimy cały nasz kod dotyczący skanowania wybranego URL:
// check-links.js
const { SiteChecker } = require("broken-link-checker");
const siteChecker = new SiteChecker(
{
excludeInternalLinks: false,
excludeExternalLinks: false,
filterLevel: 0,
excludedKeywords: ["linkedin.com", "github.com"]
},
{
"error": (error) => {
console.error(error);
},
"link": (result) => {
if (result.broken) {
if (result.http.response && ![undefined, 200, 429].includes(result.http.response.statusCode)) {
if (result.internal) {
console.error(`broken internal link ${result.http.response.statusCode} => ${result.url.original} on page ${result.base.resolved}`);
} else {
console.warn(`broken external link ${result.http.response.statusCode} => ${result.url.original} on page ${result.base.resolved}`);
}
}
}
},
"end": () => {
console.log("CHECK FOR BROKEN LINKS FINISHED!");
}
}
);
siteChecker.enqueue("http://localhost:8000/");
Teraz prześledzimy sobie co dzieję się w powyższym kodzie.
Importujemy klasę SiteChecker i tworzymy jej nową instancję z obiektem konfiguracyjnym i eventami, na które chcemy nasłuchiwać.
Chcemy skanować linki wewnętrzne, czyli należące do naszej strony (którą w linii 33 będziemy nasłuchiwać, czyli wywołamy na naszym URL skanowanie) oraz linki zewnętrze, czyli nie należące do naszego serwisu, np. google.com itd.
Następnie wybieramy poziom filtrowania, który ustawiliśmy na 0, tzn., chcemy skanować tylko tagi a oraz area, które muszą zawierać atrybut href.
Jest kilka linków, których nie chcemy skanować, a będzie to Linkedin (który zawsze wyrzuci błąd) oraz Github, który prędko zacznie wyrzucać błąd 429. W excludedKeywords możemy też używać glob patterns (ale nie wszystkich) z użyciem biblioteki matcher.
Następnie zdefiniowaliśmy eventy na które chcemy nasłuchiwać. Jest ich sporo, ale nas najbardziej interesują tylko trzy: error, link i end.
Event link zostanie wyemitowany za każdym razem, gdy skanowanie linku zakończy się. Wewnątrz tego eventu mamy dostęp do informacji o przeprowadzonym skanowaniu, w tym o sukcesie lub błędzie:
"link": (result) => {
if (result.broken) {
if (result.http.response && ![undefined, 200, 429].includes(result.http.response.statusCode)) {
if (result.internal) {
console.error(`broken internal link ${result.http.response.statusCode} => ${result.url.original} on page ${result.base.resolved}`);
} else {
console.warn(`broken external link ${result.http.response.statusCode} => ${result.url.original} on page ${result.base.resolved}`);
}
}
}
},
W zasadzie wystarczająca może być informacja, że link jest zepsuty, ale chcemy jeszcze przefiltrować informacje sprawdzając statusCode. Status 200 nigdy nie powinien się tutaj pojawić, ale undefined już może. Dodatkowo wykluczymy sobie status 429 o którym już wspominałem.
Dodatkowo dla zepsutych linków wewnętrznych chcemy użyć console.error, a dla zewnętrznych console.warn, aby zaznaczyć, że najważniejsze dla nas są działające linki wewnętrzne. W logach zawieramy informację o statusCode, linku który jest zepsuty result.url.original oraz na stronie na której znajduje się ten link result.base.resolved.
Nie każdy terminal będzie pokazywał poprawne kolory.
console.erroriconsole.warnmogą mieć biały font, a nie czerwony i żółty, których się spodziewamy. W celu zapewnienia takiego samego zachowania dla wszystkich programów, możemy posłużyć się biblioteką chalk.
Event end zostanie wyemitowany po ostatnim przeskanowym linku.
Przykładowo, w evencie link możemy dodawać wszystkie popsute linki do tablicy, a następnie w evencie end wyświetlić w konsoli całkowitą ilość zepsutych linków wewnętrznych i zewnętrznych.
Teraz możemy uruchomić nasz nowy plik check-links.js:
node check-links.js
Podsumowanie
Pokazałem Ci użycie biblioteki Broken Link Checker w CLI oraz w kodzie. Jak widać, jest to bardzo przydatna biblioteka. Warto od czasu do czasu sprawdzić, czy na naszej stronie wszystko działa, a jeszcze lepiej dodać taki skrypt do naszego CI.
Zapraszam do komentowania i dzielenia się swoimi przemyśleniami 🙂